TL;DR: Es kommt darauf an, welche Zielgröße man optimiert, Radwegbenutzer oder vermiedene Fahrbahnradler.
Deutsche Twitterspießer nörgeln unter dem Hashtag #runtervomradweg über geparkte Autos und andere Hindernisse auf Radwegen und Radstreifen. Manchmal feiern sie auch das gleichermaßen verbotene und wegen der Sichtbehinderung für vorbeifahrende Radfahrer gefährliche Parken links neben einem markierten Radstreifen als vorbildlich. Das finnische Gegenstück dazu heißt #kuinkesäkeli und seine Anhänger klagen vor allem über Schnee, der auf Radwegen liegen bleibt.
Subjektiv ist der Ärger über vermeidbare Hindernisse leicht nachzuvollziehen, wenngleich zu einem über die Verkehrsbehinderung schimpfenden Tweet immer zwei gehören, nämlich auch derjenige, der erst einmal anhält und ein Foto macht. Hindernisse gehen jedem auf die Nerven, das Ausweichen kann gerade auf Radwegen schwierig bis unmöglich sein und wer bei der Radwegbenutzung einen Sicherheitsgewinn fühlt, sieht sich seiner Dividende beraubt.
Brutalparker und Schneehaufen sind jedoch nicht bloß Ärgernisse des Alltags, sondern auch politisch: Sie stehen uns nicht nur konkret beim Radfahren im Weg, sondern auch im übertragenen Sinne auf dem Weg in ein Fahrradparadies, in dem wir alle gemeinsam die Hyggeligkeit Kopenhagener Radwege genießen, bis der Fahrradstau vorbei ist. Um so mehr stellt sich die Frage, warum niemand etwas tut. Den einen wie den anderen Hindernissen könnte man durch konsequentes behördliches Handeln und den regelmäßigen Einsatz von Räumfahrzeugen beikommen, was jedoch systematisch unterbleibt (Update: siehe auch den Nachtrag am Ende).

Aufschlussreicher als das Wehklagen über den Verfall der Sitten und fortwährendes Betteln um „mehr, bessere, sichere Radwege“ (neudeutsch: „Protected Bike Lanes“) ist eine ökonomische Analyse. Hinter systematischem Handeln und Unterlassen, gerade von Organisationen und Institutionen, stecken Anreizstrukturen, die dieses Handeln oder Unterlassen fördern. Wer sie nicht versteht, riskiert Überraschungen.
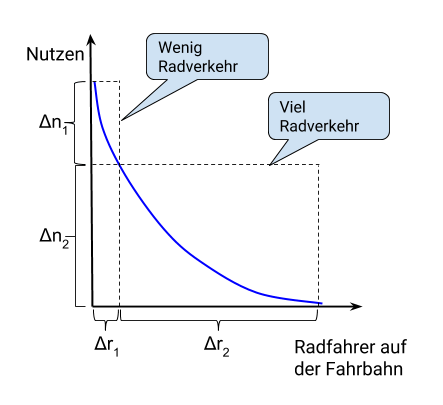
Radaktivisten gehen häufig von einem Einladungsmodell aus. Der Nutzen von Radwegen – am besten eines zusammenhängenden Radwegenetzes – bestehe darin, das Radfahren objektiv und subjektiv sicherer zu machen und damit Menschen zum Radfahren zu bewegen, die sonst das Auto oder den öffentlichen Nahverkehr benutzten würden. Dieser Nutzen steigt zu Beginn am schnellsten, wenn die ersten Radfahrer auftauchen, die nach dem Einladungsmodell sonst gar nicht auf dem Rad säßen. Als frei skizzierter Funktionsgraph sieht das so aus:

Der Nutzen n wächst mit der Zahl der Radwegbenutzer r. Der Anstieg erfolgt jedoch nicht linear, sondern er verlangsamt sich um so mehr, je weiter die Zahl der Radfahrer wächst. Begonnen bei 0 verspricht eine geringe Erhöhung Δr1 der Radfahrerzahl zunächst einen im Verhältnis dazu hohen Nutzengewinn Δn1. Demgegenüber fällt der zusätzliche Gewinn Δn2 aus einer weiteren, viel größeren Erhöhung der Nutzerzahl um Δr2 vergleichsweise bescheiden aus. Solch eine Kurve erhält man, wenn man das Nutzenwachstum nach der prozentualen Steigerung bemisst, denn bei kleinen Ausgangswerten ist die Vervielfachung leicht.
Aus der Perspektive dieses Modells müsste man Hindernisse auf Radwegen radikal beseitigen, auch wenn sie, wie Schnee im finnischen Winter, nur wenige Radfahrer betreffen. Weniger radikal ginge man nach dieser Logik gegen überfüllte Radwege vor, denn sie wären kein Problem, sondern Zeichen des Erfolgs. Wie das Foto aus Kopenhagen oben andeutet, ist dies tatsächlich der Fall – der Stau auf dem Radweg wird als nachahmenswertes Vorbild herumgereicht und er ist natürlich etwas ganz anderes als ein Lieferwagen, dem mal drei Radfahrer ausweichen müssen.
Eine bessere Erklärung für die unterlassene Räumung liefert das Verlagerungsmodell. Anders als das Einladungsmodell misst es den Nutzen von Radwegen daran, wie effektiv der übrige Fahrzeugverkehr von Radfahrern befreit wird. Am nützlichsten sind Radwege demnach, wenn kein Radfahrer mehr im Kfz-Verkehr zu finden ist. Für diese Sicht können beispielsweise Unfallzahlen sprechen, die mit sinkendem Anteil der Radfahrer am Fahrzeugverkehr abnehmen, wenn auch nicht unbedingt proportional. Als Funktionsgraph skizziert sieht dieses Modell ungefähr so aus:
Auch hier tritt der höchste relative Nutzengewinn am unteren Rand ein – wer den letzten Radfahrer loswird, bekommt eine Autobahn. Jedoch spielt nun die Ausgangssituation eine Rolle: Je weniger Radfahrer ursprünglich unterwegs sind, desto weniger lassen sich überhaupt von der Fahrbahn weg verlagern, egal wohin, und desto geringer fällt deshalb der maximal erzielbare Nutzengewinn aus. Dabei kommt es nicht darauf an, ob die verlagerten Radfahrer auf einem Radweg wieder auftauchen, auf dem Gehweg, in der U-Bahn oder hinterm Lenkrad eines Autos. Wer gleich eine Autobahn baut, muss übers Radfahren gar nicht erst nachdenken.
Das Verlagerungsmodell kann erklären, wieso Radwege ungeräumt bleiben: Schnee und Brutalparker mögen die Radfahrer stören, doch das ist dem Modell egal, denn das Modell dreht sich um Störungen durch Radfahrer. Die aber bleiben aus: weil die Straße ohnehin nicht ausgelastet ist und den Radverkehr aufnehmen kann, weil es insgesamt nicht genügend Radfahrer gibt, um ernsthaft zu stören (statt nur mit ihrer Anwesenheit die Aufführung von Verletzheitsszenen zu provozieren) oder weil ängstliche Radfahrer auch ohne Radweg fernbleiben und sich das Nutzenmaximum so ganz von alleine und kostenlos einstellt. Und wo sich die Radfahrer ausnahmsweise einmal nicht selbst wegräumen, muss man nicht gleich angemessene Infrastruktur bauen. Etwas Farbe oder ein paar Verbotsschilder kosten viel weniger und erreichen dasselbe.
Nichts sei umsonst, heißt es, doch wenn das Optimierungsziel ist, möglichst wenig Radfahrer auf der Fahrbahn zu haben, dann kommt man sehr günstig weg. Jede Infrastrukturlösung ist viel teurer als das Nichtstun und leistet gemessen an abgewehrten Radfahrern doch nur dasselbe wie Untätigkeit und Verbote. Deswegen könnt Ihr mehr gute und sichere Radwege fordern solange ihr wollt – Ihr werdet sie nicht bekommen, denn sie rentieren sich nicht. Stattdessen muss man das Ziel der fahrradfreien Fahrbahn über den Haufen werfen und einen fahrrad-, fußgänger- und anwohnerfreundlichen Kfz-Verkehr zur Regel machen. Von dieser Basis aus mag man dann überlegen, welche Verkehrswege auch ganz ohne Autos auskommen.
PS: Die L-IZ hat Zahlen zur behördlichen Duldung des Brutalparkens in Leipzig zusammengetragen: Übers Jahr bemerkt das Ordnungsamt dort ca. 2000 Falschparker auf Radverkehrsanlagen, das sind im Mittel fünfeinhalb pro Tag oder im Jahr einer pro dreihundert Einwohner. In der Regel bleibt es dann beim Knöllchen; abgeschleppt wurden von Rad- und Fußverkehrsanlagen insgesamt nur 110 Fahrzeuge in drei Jahren oder drei pro Monat. Die Stadt hat an die 600.000 Einwohner.

{kind=link}